ついに実践「インデックス編」
ついに実践「インデックス編」
SQLチューニングの目的は「実行速度の向上」。
それはだいたいにおいて「アクセスブロック数の低減」。
※「ディスクブロック」よりも「メモリブロック」にアクセスした方がパフォーマンスがよいが、今回はスナップショットはとらないので考えないこととする。
(1)抽出レコード数が多く、フルテーブルスキャンになっている。
◆「フルテーブルスキャンが一番効率がいい可能性あり」
抽出レコード数が多い場合は、シングルブロックアクセスになるインデックススキャンよりもマルチブロックアクセスを行うフルテーブルスキャンの方が効率がいい。
※インデックスはキー値を追うので、まとめ取り(マルチブロックアクセス)が出来ないと考えればいいか?
実際に何割?というのはブロックサイズやレコード長次第のようなので、都度判断が必要。
ただし、抽出列をすべてインデックスに含めることが可能であれば、全索引スキャンの検討も可能。
似たものに高速全索引スキャンもある。
| スキャン方法 | 全索引スキャン | 高速全索引スキャン |
|---|---|---|
| アクセス方法 | シングルブロックアクセス | マルチブロックアクセス |
| 順番 | 保証されている | 保証されていない。ORDER BY句が指定されている場合はデータ取得後にソートが実行される。 |
| パラレルスキャン | 不可能 | 可能 |
| 制約 | - | 指定した列のうち少なくとも1つはNOT NULL制約が必要 |
(2)抽出条件の列にインデックスが張られていない
◆「列のカーディナリティが高ければインデックス張りたい」
カーディナリティが低い場合はかえって遅くなったり(インデックス→テーブルの2度手間、マルチブロックアクセスできないetc.)、パフォーマンスを意識しなくていい機能だったり、頻度が低い機能の場合はインデックス更新のコストがネックになったりすることもある。
※カーディナリティは判断が若干複雑で、
- 高くても偏っており、大体が多数派データの抽出ならフルテーブルスキャンの方がいい。
- 低くても偏っており、大体が少数派データの抽出ならインデックスの効果がある。
(3)NULL値が抽出条件
◆「NULL値ではインデックスが作れない。が、手はある」
- ビットマップインデックスを使う。
OLTP系の場合は基本使用不可。 - 複合インデックスの第2キー以降にNULL値が含まれる列を指定する。
第1キーがNULLでなければインデックスは作られるので、インデックスによる検索が可能になる。 - ファンクションインデックスを利用し、NULL変換した結果をインデックスにする。
使用ルールを明確にしてチーム内で共有しておかないとぼろぼろになりそう。
(4)インデックス列を変換してる
◆「インデックス列はそのまま使おう」
うっかり系と知らなかった系かな?
| うっかり系 | 暗黙型変換。「インデックス列(文字列)=1」(シングルクォーテーション付け忘れ)とかで、インデックス列を型変換しちゃってる場合。 |
|---|---|
| 知らなかった系 | 「インデックス列 || 文字列」、「SUBSTR(インデックス列, 1, 2)」とか。 |
うっかり系は直せばいいとして、知らなかった系は
- インデックス列でない辺の加工で対応する。
- ファンクションインデックスにする。
- INDEXヒントを使用する。ただしインデックス列にNOT NULL制約が付いている必要がある。
(5)中間一致・後方一致な抽出条件
◆「前方一致ならインデックス使えるんだけど」
とはいえ、使いたいときはあるよね。
- INDEXヒントを使用する。ただしNOT NULL制約云々。
- OracleTextを使用する。テキスト検索専用のインデックスみたいなやつ。
(6)否定条件「!=」「<>」の使用
◆「別の条件に書き換えられないかな」
書き換えられない場合は、
- INDEXヒントを使用する。ただしNOT NULL制約云々。
(7)抽出条件1と2で指定している列がインデックス1と2に分かれている
◆「複合インデックスの方がいいんじゃない?」
このインデックスの状態のままインデックスを使うとなると、インデックス・マージということになるが、
- 「抽出条件1で走査したインデックス1」と「抽出条件2で走査したインデックス2」をマージして結果を取得する(インデックス・マージ)
- 「抽出条件1で走査したインデックス1」に対して抽出条件2で走査する
※2.のほうがパフォーマンスがいいことが多い気がする。
(抽出条件1でかなり絞られるのなら2.の方がいいし、絞られないのならそもそもフルテーブルスキャンの方がいいのではないだろうか)
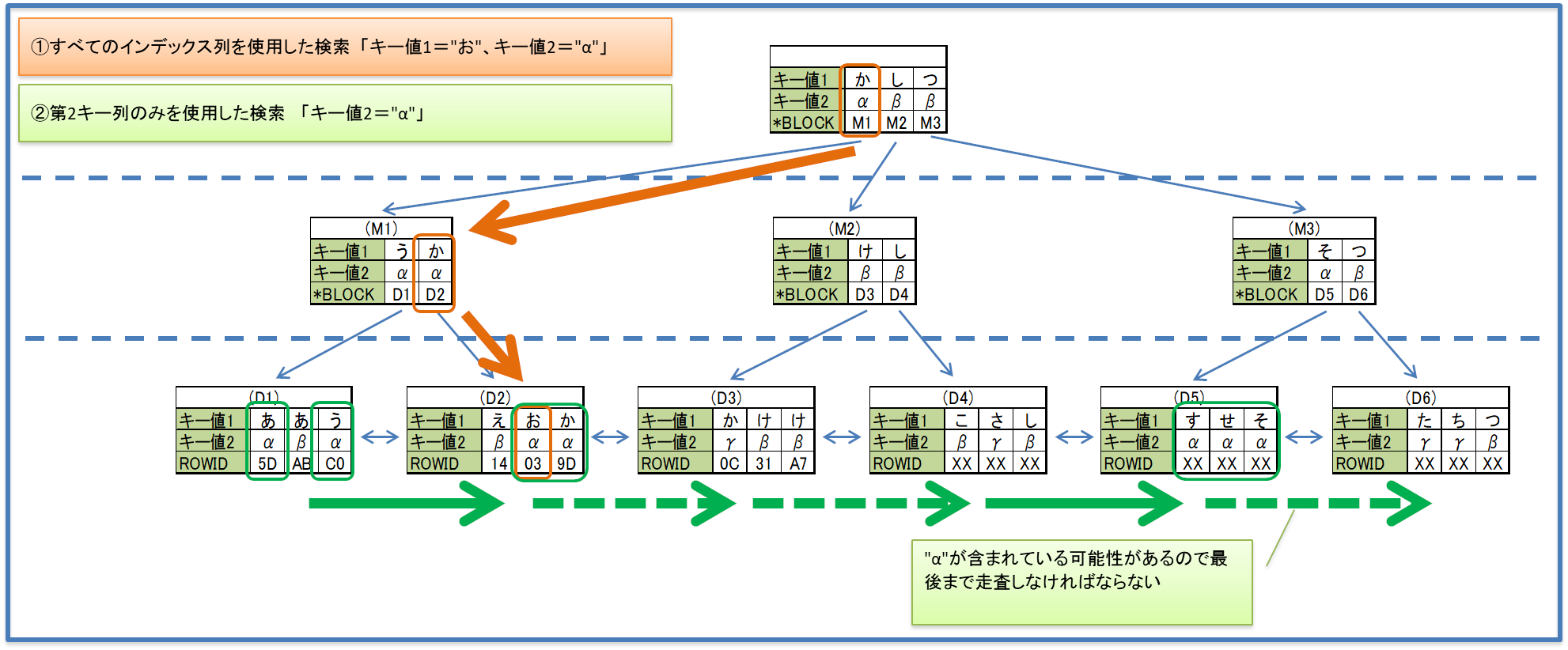
(8)複合インデックスの注意事項
◆「インデックス列の一部しか使用しない場合は大して速くならない場合もある」
◆「データが絞り込まれやすい列から順番にインデックス列にした方が効果的」
◆「基本的に複合インデックスの第1キーに指定している列は別途インデックスを張る必要はない」
インデックス列すべて使う検索の場合はルート・ブロックから順番に走査するが、先頭キー列を使わず、途中のキー列のみを使用する場合は多くのリーフ・ブロックにアクセスする。(スキップスキャン)
例えば、3つの複合インデックスの場合、
| ○ | 「第1キー使用」、「第1キー、第2キー使用」、「第1キー、第2キー、第3キー使用」 |
|---|---|
| × | 「第2キー使用」、「第2キー、第3キー使用」、「第3キー使用」 ※すべてのリーフ・ブロックにアクセスすることになる |
| △ | 「第1キー、第3キー使用」 ※第1キーである程度リーフ・ブロックを絞り込める |
※×と△がスキップスキャンになる。
(9)ビュー、シノニム
◆「インデックス使うよ」
ビューやシノニムでも元になっているテーブルのインデックスが使用されるよ。
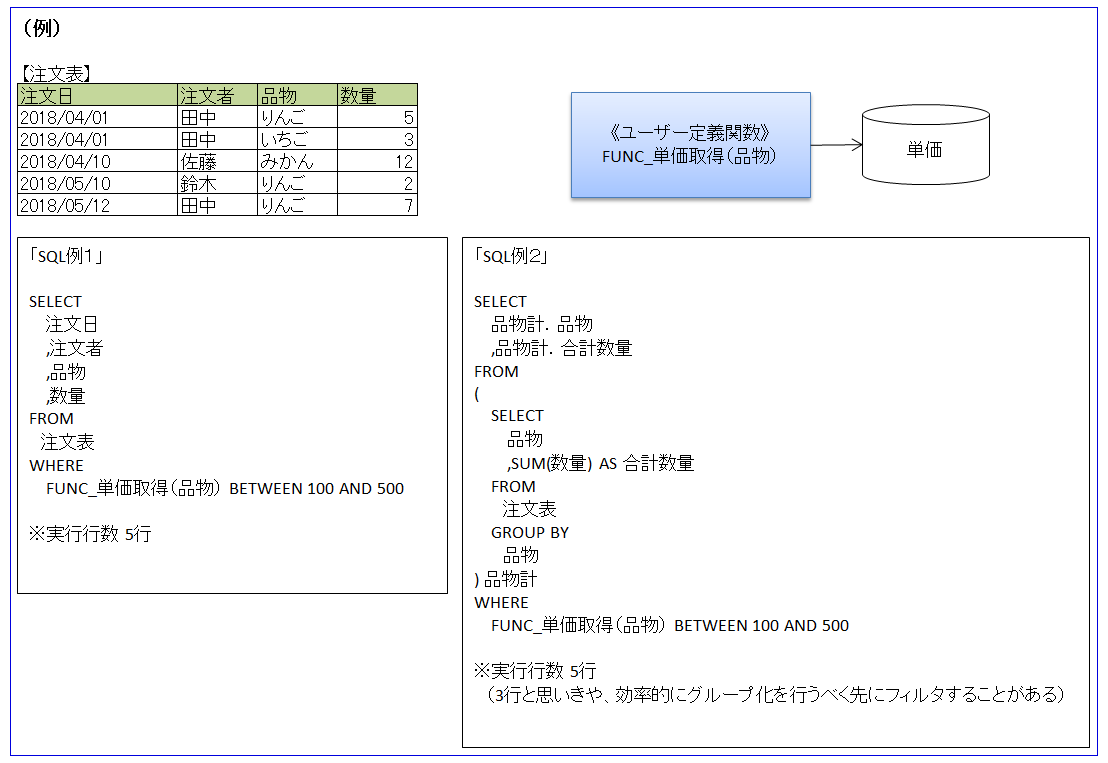
(10)関数
◆「関数が実行される行数に注意」
特にテーブル問合せなどの処理をユーザー定義関数にしている場合、実行される行数が多くなるとパフォーマンスの劣化が激しい。
実行計画の「Rows」が実行行数の目安。