SQLチューニングといえばインデックス。
SQLチューニングといえばインデックス。
データアクセスを高速にするためにあらかじめ用意しておくデータ群がインデックス。
特定の列のみのレコードとなるので、走査時のアクセスブロック数が抑えられ、高速なデータアクセスとなる。
1.B*Tree(Balanced Tree)索引
●説明
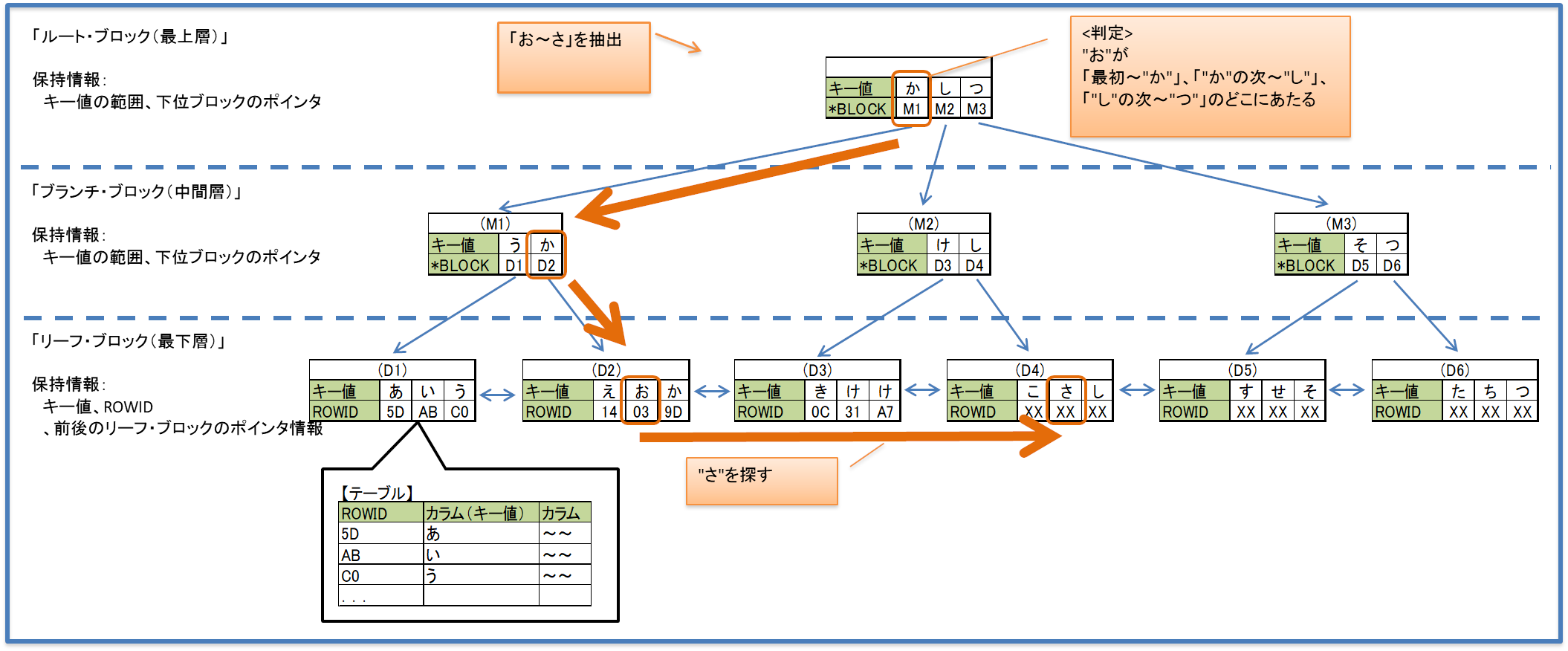
ツリー構造のインデックス。上位ブロックには下位ブロックの最後のキー値とそのブロックのポインタ情報を持つ。
※オレンジは走査の例
●メリット
・比較的データ量の多いテーブルに対して高パフォーマンスが期待できる。
・カーディナリティが高い列に対して高パフォーマンスが期待できる。
※「カーディナリティが高い」=「値の種類が多い」
・範囲検索に対して高パフォーマンスが期待できる。
●デメリット
・データの追加・更新・削除時にオーバーヘッドが発生する。
・キー値にNULLを指定できない。抽出条件「IS NULL」ではインデックスが使用されない。(複合インデックスの場合は例外あり)
2.ビットマップ索引
●説明
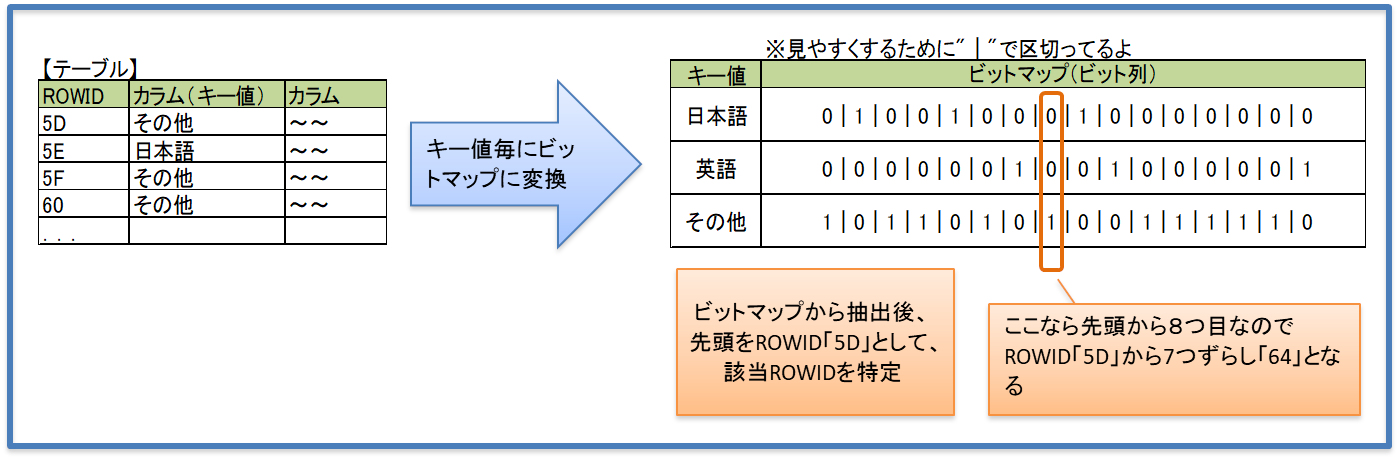
キー値ごとにROWIDに対応したビットマップを作成する。
●メリット
・カーディナリティが低い列に対して高パフォーマンスが期待できる。
・AND条件やOR条件でも高速。(ビット演算後に対応するROWIDを取得するため)
・NULL値の指定が可能。
●デメリット
・範囲検索は有効に機能しない。
・データの追加・更新・削除時にはビットマップのグループ単位でロックがかかるため、ロック待ちによるパフォーマンスの低下が起こりやすい。
※OLTP系で更新がかかるテーブルへの使用は控えるべき。
3.ファンクション索引
B*Tree索引のキー値を関数結果で保持する方法。
B*Tree索引では「TO_CHAR(キー値)」のように使用すると、関数結果で検索するためインデックスが使用されない。
なので、あらかじめ「TO_CHAR(キー値)」の結果をキー値としてインデックスを作成する。
●メリット
・関数を使用した検索でも索引が使用可能。
●デメリット
・集計関数は使用できない。同一レコードの列のみ参照可能。
・VARCHAR2、RAW、LONGRAWなどの長さが不明のデータ型は使用できない。
4.逆キー索引
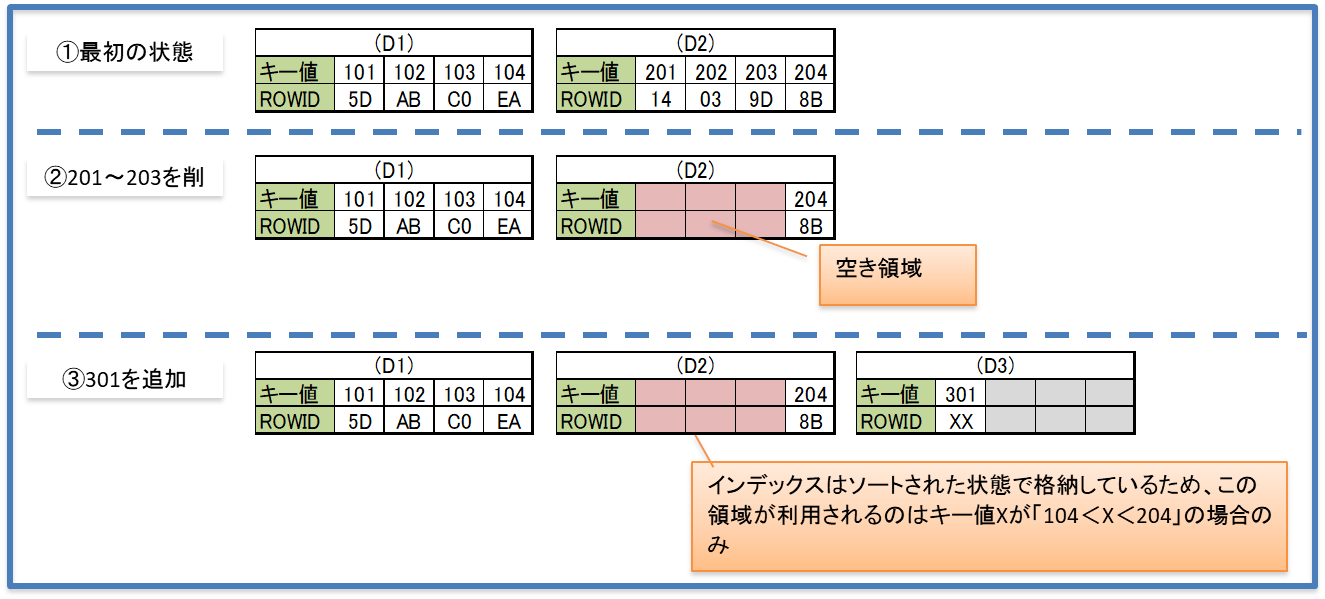
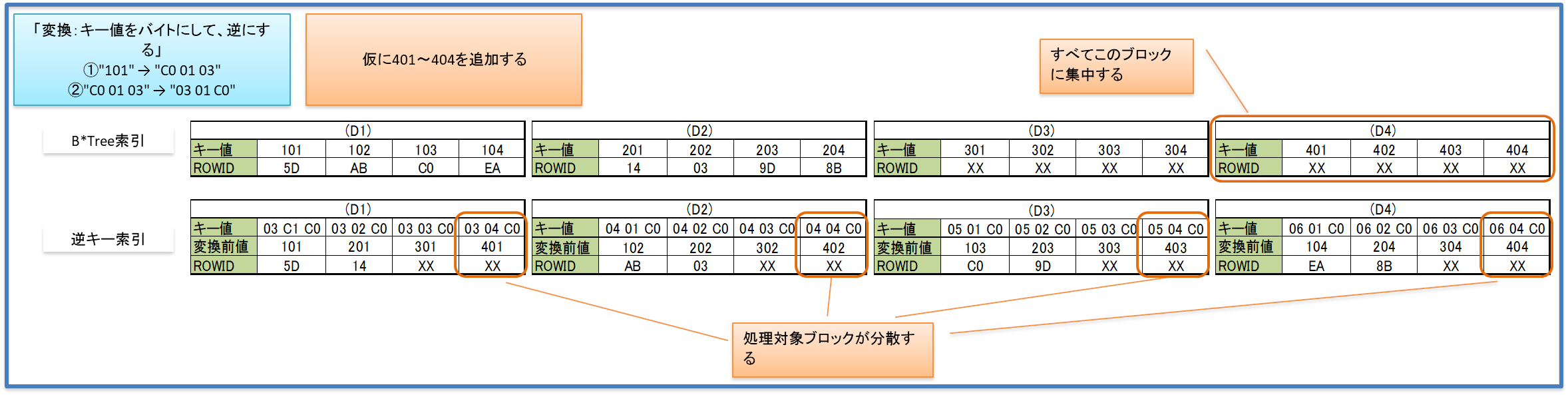
B*Tree索引では連続したキー値を追加した場合、特定のリーフ・ブロックに処理が集中してしまい、パフォーマンスの低下につながる。
キー値を変換してブロックに格納することにより、処理を分散することを可能にした方法。
B*Tree索引ではシーケンスなどの連続したキー値の場合、削除されても新しく追加される番号は最大値+1などのため、削除されたキー値が格納されたブロックは再利用されない。
逆キー索引では分散されているため、再利用の可能性が高くなる。
●メリット
・ブロックの競合が低減され、パーフォーマンスが期待できる。
・索引の格納効率があがり、再構築頻度が減少する。
●デメリット
・範囲検索ができない。
※以下に削除後のブロック再利用について補足する。