
 SQLチューニング(実行計画)のお勉強はじめます。
SQLチューニング(実行計画)のお勉強はじめます。
いままでだましだましだったのを反省し、1回ちゃんと勉強してみよう。
Oracleを使用するので、ところどころOracleに特化した記述になっているので注意。
1.チューニングの種類
ざっと以下3種類
(1)テーブル構造のチューニング
「データ量が多い場合のテーブル分割(キー値前半・後半とか)」や「ある程度情報をまとめて格納しておく(正規化すりゃいいってもんじゃない?)」、「リアルタイム集計(SQLで集計)から夜間バッチで集計し結果を格納」などのアプローチ。
(2)SQLのチューニング
書き方によるパフォーマンスの改善。
(3)メモリ、ディスクI/O、OSのチューニング
設定値変更やディスク分散などのアプローチ。
一介のプログラマーが手を出しやすい「(2)SQLのチューニング」について勉強をすすめることとする。
2.実行計画の抽出
(1)実行計画の作成
EXPLAIN PLAN FOR
SELECT ~~(2)作成された実行計画の出力
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY())実行計画の実体はPLAN_TABLEというテーブル。
「DBMS_XPLAN.DISPLAY()」は見やすく整形してくれる関数。
(3)実行計画の読み方
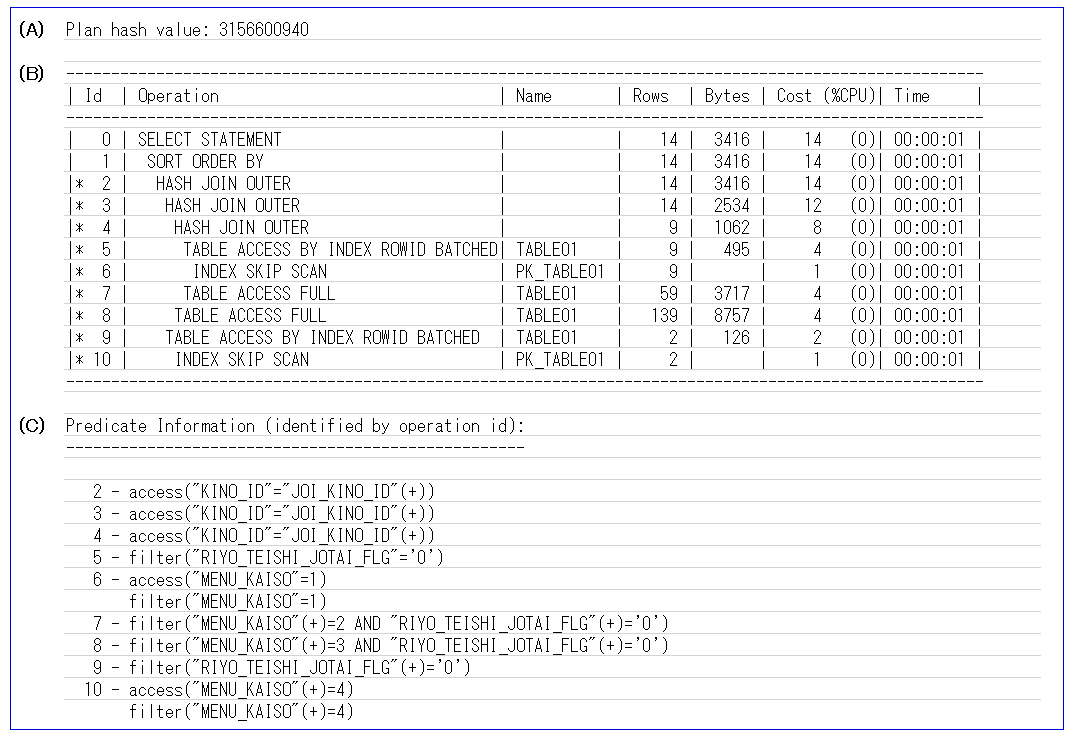
●パート
| (A) | 実行計画の値。複数の実行計画を保持することもできるのでそのための認識ID。 |
| (B) | 実行計画。アクセスパスにより処理内容を表示。 |
| (C) | 述語。実行計画の補足情報。番号はアクセスパスのIdに対応。 |
●(B)実行計画の読み方
- 右側にある(レベルの高い)アクセスパスが先に実行される
- 同じレベルの場合、上のアクセスパスが先に実行される
- アクセスパスは別のアクセスパスを含むことがある
●(C)述語の読み方
| 「access」 | リーフノードの走査の開始と終了の条件を表す。 |
| インデックス操作に対する「filter」 | 上記Id.6のようにインデックスアクセスパスに対するフィルタ述語。 リーフノード走査の時に適用される。 Oracleはフィルタ述語をアクセス述語としても表示するので、フィルタ述語と同内容(または一部)がアクセス述語に表示されることがあるが、あくまでフィルタ述語。 |
| テーブル操作に対する「filter」 | 上記Id.5のようにテーブルレベルのフィルタ述語。 フィルタするためにまずテーブルからレコードをロードする必要がある。 |
●上記実行計画の説明

(4)主要な記載項目
| 種類 | 表示項目 | 概要 |
|---|---|---|
| テーブル・アクセス (※1) |
TABLE ACCESS FULL | テーブルのすべての行を読み込む |
| TABLE ACCESS CLUSTER | 索引クラスタ経由でのアクセス(※2) | |
| TABLE ACCESS HASH | ハッシュクラスタ経由でのアクセス(※2) | |
| TABLE ACCESS ROWID | ROWIDを使用したアクセス | |
| インデックス | INDEX UNIQUE SCAN | ユニーク・インデックスを等号検索する(Bツリー走査のみ) |
| INDEX RANGE SCAN | インデックスを範囲検索する(Bツリー走査&リーフノードチェーン) | |
| INDEX SKIP SCAN | 複合インデックスで第1キーを条件としていない場合のインデックス利用 | |
| 結合 | CONNECT BY | 自己結合で階層型クエリーが行われる |
| MERGE JOIN | ソート/マージ結合が利用される | |
| NESTED LOOP | ネステッド・ループ結合が利用される。最初のテーブルが外部テーブル。 | |
| HASH JOIN | ハッシュ結合が利用される | |
| 集合演算 | MINUS | 最初の結果セットから2つ目の結果セットに含まれている行が取り除かれる。 |
| UNION ALL | 2つの結果セットが縦にマージされる | |
| UNION | 2つの結果セットが縦にマージされ、重複した行が取り除かれる。 | |
| ソート | SORT JOIN | マージ結合をするためにソートされる |
| SORT UNIQUE | 重複する行を取り除くためにソートされる | |
| SORT GROUP | GROUP BY句が使われた時にソートされる | |
| SORT ORDER | ORDER BY句が使われた時にソートされる | |
| その他 | MATERIALIZE | WITH句のSQLを一時表にする(※3) |
| INLINE | WITH句のSQLをインラインビューにする |
※1.”BATCHED”について
「TABLE ACCESS BY INDEX ROWID BATCHED」などのように”BATCHED”が付くことがある。
これは「Batchアクセス」を行っていることを表す。
| 「Batchアクセス」 | インデックススキャンの効率を上げるための手法の1つ。直訳:「一塊」。 インデックス範囲スキャンするときのクラスタ化係数を改善するために、ROWIDをデータ・ブロック順に並べ替えてまとめてアクセスする方法。I/O待機を削減するが、結果が索引の順番を保障できなくなる。 |
※2.クラスタについて
直訳:「集団」
2つ以上のテーブルを結合した(まとめた)結果を格納したデータ。
格納した領域をクラスタブロックという。
●クラスタの種類
| (1) 索引クラスタ | 複数のテーブルを共通の列(クラスタキー)で結合したデータ。 よく使うテーブルの組み合わせをクラスタにし、よく使う抽出条件列をクラスタキーにするとパフォーマンスが向上する。 |
| (2) ハッシュクラスタ | クラスタキーをハッシュ値にしたクラスタ。 大量データから数件抽出時にパフォーマンスが向上する。 |
※3.一時表について
MATEREIALIZEヒントを指定すると一時表として本体SQLの問合せ前に実体化する。
指定しない場合、WITH句のSQLを一時表とするか、本体SQLのインラインビューとして扱うかはオプティマイザ次第。
WITH句のSQLが複数回使用され、有効なインデックスがなく、レコード数がある程度絞り込まれている場合、実体化してから使用した方が効率がいいことがある。
(実体化するとメモリを消費するし、インデックスがなくなるので、使いどころは難しい)
WITH句のSQLのSELECT句の後ろに記述する。
※4.実測する場合
バッファ・キャッシュには、テーブルやインデックスなどのデータブロックのキャッシュが保存されているので、
実測する場合にはバッファ・キャッシュ上のデータを消去しないと、正しい結果が得られない。
SYSユーザーでログインし、「alter system FLUSH BUFFER_CACHE」を実行。